参考:
使用Magellan进行数据匹配过程如下:
假设有两个数据源为A和B,
A共有四列数据:(A_Column1,A_Column2,A_Column3,A_Column4)
B共有五列数据: (B_Column1,B_Column2,B_Column3,B_Column4,B_Column5)
假设A_Column1和B_Column1是相关的,而A_Column2和B_Column2相关的
1、首先建立合并列表
分别在A和B数据中建立一个混合列mixture
在A中 mixture = A_Column1 + A_Column2 就是把 A_Column1 和 A_Column2两列的数据合并到mixture列里面,
同理,在B中 mixture = B_Column1+ B_Column2

2、寻找一个候选集
这个过程就是使用重叠系数连接两个表,我们可以使用混合列创建所需的候选集(我们称之为C)。

注意:这个过程中threshold这个参数代码这要C这个集合中要创建一列_sim_score ,表示相似度分数,如何经过匹配_sim_score 的数据小于0.65,那么就是不合格的,说白了就是相识度很小,
threshold这个设置的过多大,导致可能C的集合很小,值越大代表数据相识度越大 ,threshold最大值是1,代表匹配数据完全一样,值越小代表数据相识度越小,如果所有数据的匹配结果都小于threshold的值,那么
C就是空集合,因此这个值要根据选择的匹配列数进行设置。
3、指定要素
就是指定在py_entitymatching程序包中哪些列对应于各个数据帧中的要素

4、拦截工具故障排除
确保候选集足够松动,能够容纳并不十分接近的电影配对。如果不是这样,那么可能我们已经清除了可能潜在匹配的配对
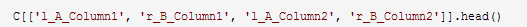
5、从候选集采样
目标是从候选集中获取一个样本,并手动标记抽样候选者;也就是指定候选配对是否是正确的匹配。

要在导出的labeled.csv文件中增加一个label列,根据_sim_score列的数据和实际数据情况,来人为的判断是否是正确的匹配,如果是则在label列中填入数值1,否则,填入数值0
注意:这个label.csv数据集合实际上作为下面机器学习一个训练集,因此这个label列数据之间影响下面机器学习的效果。

6、机器学习算法训练
下面用了几种机器学习算法

在应用任何机器学习方法之前,我们需要抽取一组功能。幸运地是,一旦我们指定两个数据集中的哪些列相互对应,py_entitymatching程序包就可以自动抽取一组功能。指定两个数据集的列之间的对应性,
将启动以下代码片段。然后,它使用py_entitymatching程序包确定各列的类型。通过考虑(变量l_attr_types和r_attr_types中存储的)各个数据集中列的类型,并使用软件包推荐的编译器和类似功能,我们可以抽取一组
用于抽取功能的说明。请注意,变量F并非所抽取功能的集合,相反,它会对说明编码以处理功能。

考虑所需功能的集合F,现在我们可以计算训练数据的功能值,并找出我们数据中丢失数值的原因。在这种情况下,我们选择将丢失值替换为列的平均值。

使用计算的功能,我们可以评估不同机器学习算法的性能,并为我们的匹配任务选择最佳的算法。

7、评估匹配质量
评估匹配质量非常重要。可以针对此目的使用训练集,并衡量随机森林预测匹配的质量。我们可以发现,我们获得最高精确性,并且能够重现测试集。

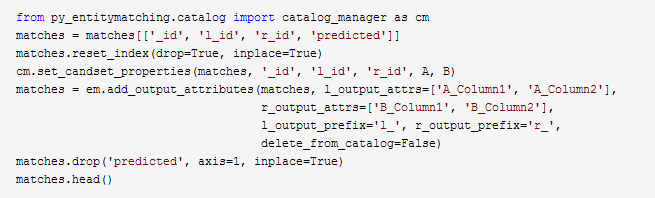
8、使用训练的模型匹配数据集
使用训练的模型对两个标记进行如下匹配

请注意,匹配数据帧包含了很多存储数据集抽取功能的列。以下代码片段移除了所有非必要的列,并创建一个格式良好的拥有最终形成的整合数据集的数据帧。